
I asked for help explaining the
slow assignments that opannotate
saw in i965_prepare_composite and I got just the help I hoped
for. Peter Lund, Phillip Ezolt, Michel Dänzer, Wang Zhenyu, and Keith
Packard each provided some helpful suggestions. Thanks to each of you!
The big slowdown was due to the various bitfield assignments resulting in successive read-modify-write cycles to the uncached memory, (often to the same location!). So every read would block and force a flush of the previous write. So we were seeing abysmal performance as the CPU performed lock-step reads and writes over the AGP bus.
The simplest fix was to just setup the desired state in local buffers on the stack and to memcpy them when finished, resulting in a nice stream of AGP writes that can benefit from write-combining.
Subsequent improvements could involve not writing out data that is identical from one call of the function to the next. And it might help to rewrite the driver code to make it more clear when it is performing IO reads, (since unintentional reads can cause such performance problems by forcing a flush of pending writes).
I've published a series of "use local structure" patches in a git branch and sent that off to the xorg mailing list for review. (Update: These improvements have now been pushed out into the upstream repository for xf86-video-intel.) Here's a chart showing the improvement:
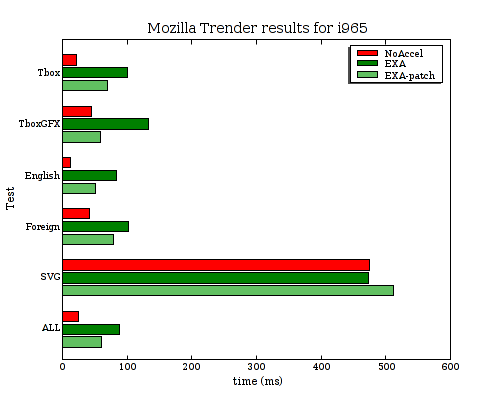
| Test | Tbox | TboxGFX | English | Foreign | SVG | ALL |
|---|---|---|---|---|---|---|
| NoAccel | 21.859 | 44.698 | 12.110 | 41.205 | 474.750 | 24.176 |
| EXA | 100.777 | 133.532 | 83.543 | 101.258 | 473.111 | 87.740 |
| EXA-patch | 69.147 | 58.795 | 51.450 | 79.048 | 511.694 | 60.086 |
So that helped a fair amount for the text-heavy tests, (although the SVG case slowed down a bit for some reason), but the overall performance is still over 4x slower than NoAccel in some cases. The profile isn't showing any single huge bottleneck anymore, but several things in the 5-8% range. Fixing things now might require a series of individual fixes that each chop another 5% problem off.
Michel also made the good suggestion that I separately profile the worst-behaving test case, so I'll pursue that next.